ICOP
cental | Louvain-la-Neuve
|
Funding: EU's Safer Internet program |
The iCOP project (funded by the EU's Safer Internet program) is developing a novel forensics software toolkit to support law enforcement agencies across the EU in identifying new or previously unknown child abuse media and its originators on peer-to-peer (P2P) networks.
The goal of the trend analysis module is twofold. First, it recognizes child sexual abuse (CSA) media from its textual descriptions such as filename, metadata, and associated web pages. Secondly, the module extracts key terms describing the CSA media. These terms are used to analyze and track topics by other modules of the iCop toolkit.
File Classification by Textual Description
The goal of the file classification is to decide if an input file contains some CSA material solely from textual descriptions of the file. This kind of classification is challenging because:
- Filenames may be meaningless, such as "0012664321.mpg"
- File text descriptions and metadata may be short or absent
- Text descriptions often use highly non-standard language (abridgments, abbreviations, spelling errors mixed with technical terms, etc.)
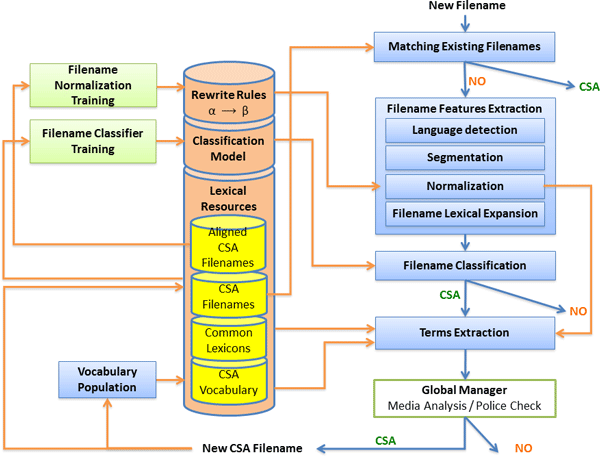
In order to deal with these and other issues we designed a sophisticated yet efficient text classification system (see figure 1). The system receives a file name, its metadata, and textual descriptions as input. First, the system checks if the file is an already known CSA media with help of database of hashes, but also with intelligent sequence matching algorithms.
If the file is known, then several advanced text processing techniques are used to extract features from the text describing the file. To do so, first text is segmented. Next, cutting-edge text normalization, and lexical semantics technology is used to represent content of the media from scarce, noisy, and misspelled text descriptions. Then a state-of-the-art statistical machine learning classifier is used to precisely separate regular files from those containing some abuse content. The classifier is trained on a huge database of file names containing CSA material. This database is provided by our collaborators from Police.
The file classification module is used to recognize newly published files in a P2P network which contain abusing content. The list of these candidate files is transferred to the Media Analysis component, where content of each file is further analyzed.
Term Extraction
For each detected child abuse media, our module returns a set of normalized terms describing it. These terms let monitors seamlessly analyze and track topics in the P2P networks. Basically, the extracted terms, are normalized lexical units extracted during the feature extraction stage (see above).
The words which were never used before for describing CSA content are also recognized. Detection of the new words helps to identify personal names, and locations related to recent victims and abuse cases. In order to detect new terms we rely on a database of CSA terms.
The database of CSA language is constructed during the training phase. It is based on specialized hand-crafted terminologies provided by Police. This initial lexicon is enriched with terms extracted from the filenames containing child abuse media. To do so, we basically run the segmentation and normalization tools used on the feature extraction stage on these files and add the most frequent terms to the CSA vocabulary. The CSA database is updated once new files containing illegal material are provided.
Researchers
- Dr. Richard Beufort
- Prof. Cédrick Fairon
- Alexander Panchenko